
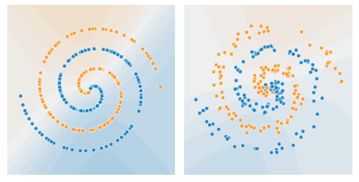
在TensorFlow Playground中,螺旋数据集是一个经典的机器学习分类问题。然而,这个数据集因其独特的结构和特征,常常给初学者和研究者带来分类上的挑战。本文将深入探讨螺旋数据集分类的难点,并分析其原因。
首先,我们来了解一下螺旋数据集的基本特性。螺旋数据集由两个类别组成,每个类别包含一个螺旋形状的数据点。这些螺旋形状的数据点在二维空间中相互交织,形成一个复杂的分布。这种分布的特点是类别之间的边界模糊,且数据点在空间中呈现出螺旋上升或下降的趋势。
螺旋数据集的复杂性主要体现在以下几个方面:
类别边界模糊:由于螺旋形状的交织,两个类别的数据点在空间中相互渗透,导致类别边界不清晰。
数据点分布不均匀:螺旋形状的数据点在空间中分布不均匀,某些区域的数据点密集,而其他区域则相对稀疏。
数据点趋势复杂:螺旋形状的数据点在空间中呈现出复杂的上升或下降趋势,这使得模型难以捕捉到数据点的真实分布。
由于螺旋数据集的上述特性,传统的机器学习模型在分类过程中面临着以下挑战:
特征提取困难:模型难以从数据中提取出有效的特征,因为数据点分布复杂,且类别边界模糊。
过拟合风险:由于数据点分布不均匀,模型在训练过程中容易过拟合,导致泛化能力下降。
参数调整困难:螺旋数据集的复杂特性使得模型参数调整变得困难,难以找到最优的模型参数组合。
在TensorFlow Playground中,我们可以利用可视化工具来观察螺旋数据集的分布和特征。通过数据分布可视化和决策边界可视化,我们可以更直观地了解数据集的复杂性和分类难题。
数据分布可视化:通过可视化工具,我们可以观察到数据点在空间中的分布情况,以及类别之间的边界模糊性。
决策边界可视化:通过调整模型参数,我们可以观察到决策边界的变化,从而了解模型对数据集的分类能力。
使用更复杂的模型:尝试使用具有更多隐藏层和神经元的模型,以提高模型对数据特征的捕捉能力。
数据预处理:对数据进行归一化或标准化处理,以降低数据分布不均匀的影响。
正则化技术:采用正则化技术,如L1、L2正则化,以降低过拟合风险。
交叉验证:使用交叉验证方法,如k-fold交叉验证,以提高模型的泛化能力。
螺旋数据集在TensorFlow Playground中是一个具有挑战性的分类问题。其复杂的数据分布和特征使得模型在分类过程中面临诸多困难。通过深入分析数据集的特性,并采取相应的解决策略,我们可以提高模型在螺旋数据集上的分类性能。同时,这也为我们在实际应用中解决类似分类问题提供了有益的参考。























